LLM API应用和封包-简单的提示词工程20250310
提示词工程
OpenAI Help中提供的prompt基础
使用更新的模型,确实可以降低提示词的依赖程度
使用“”“或者###分隔符来索引你输入的待处理文本
使用正向提示,而非负面排除,来控制文本质量
设置合理的temperature,确切性计算(数学解题、查找表格、查找文档内容、当做事实百科使用等)一定要设置为0
真·提示词,或称之为先导词(leading words),比如让它写Python,就换到新一行,写上import。
其他的:
描述越细节越好,覆盖到各种维度。当然,可以让模型帮你生成提示词,在交互中明确自己的要求,更全面一些。
涉及到格式输出的时候,使用例子,而不是空口描述
精确阐述要求,避免前后重复和过度口语化 。特别地,使用句子数量,如“3-5句话”,来控制生成内容的长度,而非“一段话”、“多少字”之类的。
ChatGPT的提示词基础
设定角色,以聚焦当前正在处理的任务。在API中相当于设定system prompt
chain of thought类别的提示词,或者叫chain of logic prompting,人为的分解出一些前后步骤,避免直接索要结果。(当然了这个过程也是可以让模型生成的,或者在对话交互中明确)
Reasoning 模型的提示词工程
不要自己写steps、一步一步来等提示,这些会弱化模型的输出
着重于最后所要的结果,给出清晰的要求,最好是可量化的提升,这样模型在思考之中可以迭代以达到你的要求
把reasoning模型当做顶层规划者而非一个干活儿的doer,避免描述太多过程性的、如何做的具体细节内容
使用“”“等格式化输入,便于准确阅读和了解意思。
o1和o3-mini应用现状
已经开放给所有用户付费API用户使用
o1作为具有大量真实世界背景知识的旗舰reasoning模型,仍然是经过筛选的用户子集才能使用
o3-mini作为小模型,正在 加快进度开放给所有付费API用户。
何时使用reasoning模型?
相较于告诉他一步一步的做法,直接以最终的要求进行刺激。
探求多个文件中隐含的复杂关系和逻辑的时候
在多个文件之中要进行大海捞针(如处理合同、金融、法律条文)等的时候
处理一些目标宏大的问题的时候(会激发大模型反问你,要求你补充细节和information gap)
代码审查、debug、提高代码质量(写的时候用o3-mini,审查的时候用o1)
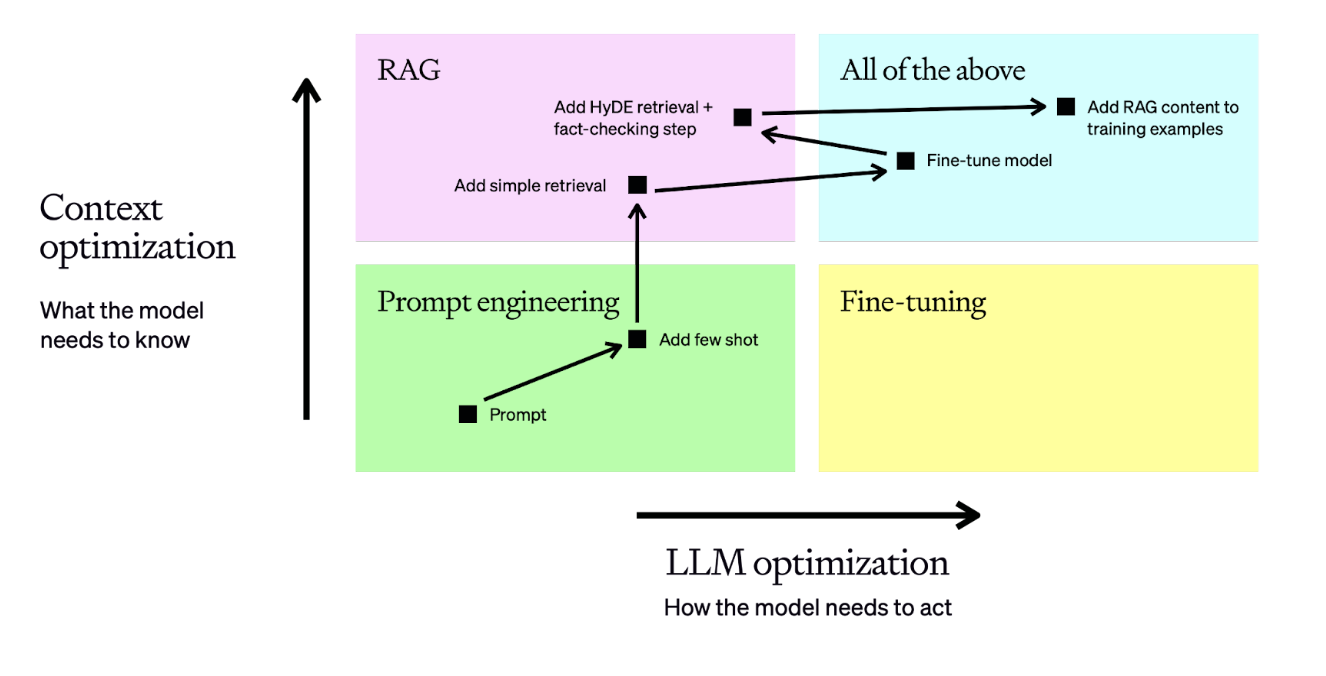
zero-shot few-shot RAG和fine-tune
以上顺序就是进行prompt所需进行的顺序。当然了,调整提示词也是其中环节之一,应该放在最前面。
谷歌搜索API OpenWebUI的联网搜索
可以自己设置避免哪些网站,可以自己设定搜索内容的数量和采信的数量。
效果:已经实现了联网搜索的流程,但是效果不尽如人意。
情况:
搜索词自动生成的不好,在prompt中应该非常明确的指出关键词,而不是让它自己生成决定
上下文宽度小,网页抓取后长度长,无效内容多。应该在投喂给LLM做输入之前,先做结构化的清洗或内容压缩、截断。使用embedding应该是不需要的,速度慢
改进方法:
从搜索API上下功夫,限制搜索内容范围
做其他的工程性工作,让联网搜索更好用
限制模型联网搜索的应用范围,在很确切的问题上再让它联网
总结:
联网功能也算是一个Agent了,效果取决于工程能力,并非模型原生能力,比不过已经封装成产品的ChatGPT的效果的。
OpenWebUI的代码解释器—远程部署的jupyter notebook
代码解释器的好处
自己写python代码,然后运行,适用于做确切的数据计算
能直接作图出图(使用plot)
利用python最强大的能力和老本行——数据分析,实现端到端的小规模多步骤自动化(算是内嵌程度比较好的Agent)
可能:office自动办公,尤其是处理excel之类的任务,可以更好的进行吧
自己部署代码解释器的好处
自己设定虚拟机沙盒空间,自己设定代码最长运行时间(默认只有60秒,处理不了大数据量的内容)